Bagian 5 Data Wrangling dengan tidyverse
Tiga sub-bab pertama dalam artikel ini merupakan bagian dari tugas STA581 dan pernah dipublikasikan RPubs.com/nurandi.
5.1 Data Wrangling
Aktivitas apa yang biasa dilakukan oleh data scientist terhadap data tabular? Barangkali menghapus kolom atau baris, melakukan kalkulasi, menambahkan kolom baru atau melakukan agregasi. Aktivitas-aktivitas tersebut sering disebut sebagai data wrangling (The OHI Team 2019) atau manipulasi data (dalam konitasi positif) yang bertujuan untuk mengubah data menjadi format yang lebih mudah digunakan atau mudah dipahami. Manipulasi data menjadi bagian tidak diterpisahkan dalam persiapan data yang umumnya membutuhkan waktu paling lama dari keseluruhan rangkaian analisis data. Skenario dalam proses ini berbeda-beda tergantung pada data yang digunakan dan tujuan yang ingin dicapai (Stobierski 2021).
5.2 R, tidyverse dan dplyr
Sebagai bahasa pemrograman populer dalam sains data, R menyediakan berbagai paket/library untuk tujuan-tujuan spesifik. Sebagai contoh, kita dapat memanfaatkan paket tidyverse; sekumpulan beberapa paket untuk ekplorasi, manipulasi dan visualisasi data (Wickham et al. 2019), yang terdiri dari paket-paket antara lain:
ggplot2: membuat grafik dan visualisasi datadplyr: manipulasi datatidyr: membentuk “tidy data”, yaitu data dalam format yang konsistenreadr: membaca berbagai data tabularpurrr: bekerja dengan fungsi dan vektortibble: bentuk lain dari data frame yang lebih modernstringr: bekerja dengan stringforcats: bekerja dengan factorlubridate: bekerja dengan data berformat tanggal dan waktu

tidyverse. Sumber gambar: Che Smith ([email protected])
Artikel ini akan fokus pada pemanfaatan paket dplyr (Wickham et al. 2021b). Paket yang dikembangkan oleh Hadley Wickham dan tim ini dipandang sebagai “grammar” yang di dalamnya tersedia sejumlah “verb” untuk menyesaikan berbagai pekerjaan terkait manipulasi data (Wickham et al. 2021a), di antaranya untuk:
- memilih kolom,
- menyeleksi baris berdasarkan kriteria tertentu,
- agregasi data,
- menghitung kolom/variabel baru,
- mengatur urutan baris, dan lain-lain
5.3 Studi Kasus: Data MovieLens
Untuk mengeksplorasi dasar-dasar manipulasi data dengan dplyr, kita akan menggunakan data MoviLens (Harper and Konstan 2015), yang bisa diperoleh dari paket dslabs. Data set ini berisi rating dari movie/film dari website MovieLens yang dikumpulkan dan dikelola oleh GroupLens, kelompok riset di Universitas Minnesota
5.3.1 Persiapan
Instalasi paket-paket yang diperlukan, yaitu tidyverse (atau cukup dplyr) dan dslabs. Instalasi paket ini sifatnya opsional. Maksudnya apabila paket tersebut sudah terinstal maka tidak perlu melakukan instalasi lagi.
install.packages(c("tidyverse","dslabs"))Lalu load paket-paket tersebut.
library(tidyverse)## -- Attaching packages --------------------------------------- tidyverse 1.3.1 --## v ggplot2 3.3.5 v purrr 0.3.4
## v tibble 3.1.3 v dplyr 1.0.7
## v tidyr 1.1.4 v stringr 1.4.0
## v readr 2.0.2 v forcats 0.5.1## Warning: package 'tidyr' was built under R version 4.1.1## Warning: package 'readr' was built under R version 4.1.1## -- Conflicts ------------------------------------------ tidyverse_conflicts() --
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()library(dslabs)Selanjutnya load data movilens dari paket dslabs
data(movielens)Sebelum memulai proses manipulasi data, sangat direkomendasikan untuk melihat bentuk dan struktur data.
Kita sudah mempunyai data movilens, yang merupakan sebuah data frame, yang dapat kita ubah menjadi tibble agar lebih mudah dalam menginspeksi data, terutama data yang berukuran besar. Sebuah tibble apabila ditampilkan dalam layar, hanya muncul maksimal 10 baris pertama, dilengkapi dengan informasi mengenai dimensi tabel, nama dan tipe kolom serta tampilan akan menyesuaikan lebar layar.
movielens <- as_tibble(movielens)
movielens## # A tibble: 100,004 x 7
## movieId title year genres userId rating timestamp
## <int> <chr> <int> <fct> <int> <dbl> <int>
## 1 31 Dangerous Minds 1995 Drama 1 2.5 1.26e9
## 2 1029 Dumbo 1941 Animation|Childr~ 1 3 1.26e9
## 3 1061 Sleepers 1996 Thriller 1 3 1.26e9
## 4 1129 Escape from New York 1981 Action|Adventure~ 1 2 1.26e9
## 5 1172 Cinema Paradiso (Nuo~ 1989 Drama 1 4 1.26e9
## 6 1263 Deer Hunter, The 1978 Drama|War 1 2 1.26e9
## 7 1287 Ben-Hur 1959 Action|Adventure~ 1 2 1.26e9
## 8 1293 Gandhi 1982 Drama 1 2 1.26e9
## 9 1339 Dracula (Bram Stoker~ 1992 Fantasy|Horror|R~ 1 3.5 1.26e9
## 10 1343 Cape Fear 1991 Thriller 1 2 1.26e9
## # ... with 99,994 more rowsAlternatif lain untuk menampilkan struktur data adalah fungsi glimpse. Fungsi ini sebenernya mirip dengan fungsi str dari paket utils.
glimpse(movielens)## Rows: 100,004
## Columns: 7
## $ movieId <int> 31, 1029, 1061, 1129, 1172, 1263, 1287, 1293, 1339, 1343, 13~
## $ title <chr> "Dangerous Minds", "Dumbo", "Sleepers", "Escape from New Yor~
## $ year <int> 1995, 1941, 1996, 1981, 1989, 1978, 1959, 1982, 1992, 1991, ~
## $ genres <fct> Drama, Animation|Children|Drama|Musical, Thriller, Action|Ad~
## $ userId <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ~
## $ rating <dbl> 2.5, 3.0, 3.0, 2.0, 4.0, 2.0, 2.0, 2.0, 3.5, 2.0, 2.5, 1.0, ~
## $ timestamp <int> 1260759144, 1260759179, 1260759182, 1260759185, 1260759205, ~Dari output di atas kita tahun bahwa data movielens terdiri dari 100004 baris dan 7 kolom, yaitu
| Nama | Tipe | Contoh | Keterangan |
|---|---|---|---|
| movieId | int | 31 | ID film |
| title | chr | Dangerous Minds | Judul film |
| year | int | 1995 | Tahun rilis |
| genres | fct | Drama | Genre/aliran (bisa terdapat beberapa genre) |
| userId | int | 1 | ID pengguna |
| rating | dbl | 2.5 | Rating |
| timestamp | int | 1260759144 | Waktu dalam format unix timestamp |
5.3.2 Operator pipe %>%
Sebelum membahas dplyr lebih lanjut, mari berkenalan dengan operator pipe %>%. Pipe merupakan operator yang berasal dari paket magrittr (Bache and Wickham 2020), yang dalam tidyverse dimuat secara otomatis.
Perhatikan perintah berikut ini.
nama_fungsi(nama_object)apabila ditulis dengan pipe, akan menjadi
nama_object %>% nama_fungsiOperator pipe sangat bermafaat untuk menuliskan banyak operasi secara sekuensial atau berurutan. Sebagai contoh, kita ingin membulatkan vektor numerik hingga dua tempat desimal, mengurutkannya dari besar ke kecil, lalu tampilkan enam elemen pertama.
set.seed(123)
number_data <- runif(n = 15, min = 0, max = 100)Dengan base R dapat kita tulis
head(sort(round(number_data, digit = 2), decreasing = TRUE))## [1] 95.68 94.05 89.24 88.30 78.83 67.76Dengan operator pipe menjadi:
number_data %>%
round(digits = 2) %>%
sort(decreasing = TRUE) %>%
head()## [1] 95.68 94.05 89.24 88.30 78.83 67.765.3.3 dplyr’s verbs
Sebagai “grammar” untuk manipulasi data, paket dplyr mempunyai setidaknya lima “verbs” utama, masing-masing mempunya fungsi yang spesifik, yaitu:
select(): memilih kolomfilter(): menyeleksi baris berdasarkan kriteria tertentusummarise(): meringkas atau agregasi datamutate(): menghitung kolom/variabel baruarrange(): mengatur urutan baris
Selain fungsi-fungsi di atas, masih banyak fungsi lain yang dapat digunakan, misalnya group_by() untuk pengelompokan data. Mari kita eksplorasi lebih lanjut.
5.3.4 Memilih kolom: select()
Ketika bekerja dengan data yang mempunyai banyak kolom, biasanya kita ingin memilih kolom-kolom tertentu saja. Hal ini bisa kita lakukan dengan memanfaatkan fungsi select()berdasarkan nama atau posisi kolom. Misalnya dua perintah berikut akan memilih kolom title, year dan genres dari movielens.
movielens %>%
select(title, year, genres)## # A tibble: 100,004 x 3
## title year genres
## <chr> <int> <fct>
## 1 Dangerous Minds 1995 Drama
## 2 Dumbo 1941 Animation|Children|Drama|Music~
## 3 Sleepers 1996 Thriller
## 4 Escape from New York 1981 Action|Adventure|Sci-Fi|Thrill~
## 5 Cinema Paradiso (Nuovo cinema Paradiso) 1989 Drama
## 6 Deer Hunter, The 1978 Drama|War
## 7 Ben-Hur 1959 Action|Adventure|Drama
## 8 Gandhi 1982 Drama
## 9 Dracula (Bram Stoker's Dracula) 1992 Fantasy|Horror|Romance|Thriller
## 10 Cape Fear 1991 Thriller
## # ... with 99,994 more rowsmovielens %>%
select(2, 3, 4)## # A tibble: 100,004 x 3
## title year genres
## <chr> <int> <fct>
## 1 Dangerous Minds 1995 Drama
## 2 Dumbo 1941 Animation|Children|Drama|Music~
## 3 Sleepers 1996 Thriller
## 4 Escape from New York 1981 Action|Adventure|Sci-Fi|Thrill~
## 5 Cinema Paradiso (Nuovo cinema Paradiso) 1989 Drama
## 6 Deer Hunter, The 1978 Drama|War
## 7 Ben-Hur 1959 Action|Adventure|Drama
## 8 Gandhi 1982 Drama
## 9 Dracula (Bram Stoker's Dracula) 1992 Fantasy|Horror|Romance|Thriller
## 10 Cape Fear 1991 Thriller
## # ... with 99,994 more rowsKita dapat menambahkan tanda minus - untuk tidak memilih kolom tersebut.
movielens %>%
select(-title, -year, -genres)## # A tibble: 100,004 x 4
## movieId userId rating timestamp
## <int> <int> <dbl> <int>
## 1 31 1 2.5 1260759144
## 2 1029 1 3 1260759179
## 3 1061 1 3 1260759182
## 4 1129 1 2 1260759185
## 5 1172 1 4 1260759205
## 6 1263 1 2 1260759151
## 7 1287 1 2 1260759187
## 8 1293 1 2 1260759148
## 9 1339 1 3.5 1260759125
## 10 1343 1 2 1260759131
## # ... with 99,994 more rowsAda sejumlah fungsi pembantu (helper function) yang bisa digunakan dalam select(), di antaranya:
starts_with("abc"): nama kolom diawali “abc.”ends_with("xyz"): nama kolom diakhiri “xyz.”contains("ijk"): nama kolom mengandung “ijk.”num_range("x", 1:3): memilih kolomx1,x2danx3.
Selain memilih kolom, select() juga dapat digunakan untuk mengubah nama kolom, misalnya
movielens %>%
select(movie_title = title, year, genres)## # A tibble: 100,004 x 3
## movie_title year genres
## <chr> <int> <fct>
## 1 Dangerous Minds 1995 Drama
## 2 Dumbo 1941 Animation|Children|Drama|Music~
## 3 Sleepers 1996 Thriller
## 4 Escape from New York 1981 Action|Adventure|Sci-Fi|Thrill~
## 5 Cinema Paradiso (Nuovo cinema Paradiso) 1989 Drama
## 6 Deer Hunter, The 1978 Drama|War
## 7 Ben-Hur 1959 Action|Adventure|Drama
## 8 Gandhi 1982 Drama
## 9 Dracula (Bram Stoker's Dracula) 1992 Fantasy|Horror|Romance|Thriller
## 10 Cape Fear 1991 Thriller
## # ... with 99,994 more rows5.3.5 Menyeleksi baris: filter()
filter() digunakan untuk menyeleksi atau memilih baris atau observasi berdasarkan nilainya. Misalnya kita ingin menampilkan film-film yang dirilis tahun 1995.
movielens %>%
filter(year == 1995)## # A tibble: 6,635 x 7
## movieId title year genres userId rating timestamp
## <int> <chr> <int> <fct> <int> <dbl> <int>
## 1 31 Dangerous Minds 1995 Drama 1 2.5 1.26e9
## 2 10 GoldenEye 1995 Action|Adventur~ 2 4 8.35e8
## 3 17 Sense and Sensibility 1995 Drama|Romance 2 5 8.35e8
## 4 39 Clueless 1995 Comedy|Romance 2 5 8.35e8
## 5 47 Seven (a.k.a. Se7en) 1995 Mystery|Thriller 2 4 8.35e8
## 6 50 Usual Suspects, The 1995 Crime|Mystery|T~ 2 4 8.35e8
## 7 52 Mighty Aphrodite 1995 Comedy|Drama|Ro~ 2 3 8.35e8
## 8 62 Mr. Holland's Opus 1995 Drama 2 3 8.35e8
## 9 110 Braveheart 1995 Action|Drama|War 2 4 8.35e8
## 10 144 Brothers McMullen, The 1995 Comedy 2 3 8.35e8
## # ... with 6,625 more rowsDalam filter(), kita dapat menggunakan berbagai operator, seperti operator dasar <, <=, >, >, == (sama dengan) dan %in% (bagian dari). Argumen filter() yang lebih dari satu dapat digabungkan dengan bolean operator, yaitu & (and/dan), | (or/atau) dan ! (not/tidak). Misalnya untuk menampilkan film-film yang dirilis tahun 1995 dan 1996 serta beraliran/genre hanya drama:
movielens %>%
filter(year %in% c(1995, 1996) & genres == 'Drama')## # A tibble: 582 x 7
## movieId title year genres userId rating timestamp
## <int> <chr> <int> <fct> <int> <dbl> <int>
## 1 31 Dangerous Minds 1995 Drama 1 2.5 1260759144
## 2 62 Mr. Holland's Opus 1995 Drama 2 3 835355749
## 3 1358 Sling Blade 1996 Drama 6 2 1109258181
## 4 31 Dangerous Minds 1995 Drama 7 3 851868750
## 5 40 Cry, the Beloved Country 1995 Drama 7 4 851866901
## 6 1358 Sling Blade 1996 Drama 8 0.5 1154474527
## 7 26 Othello 1995 Drama 9 3 938628655
## 8 1358 Sling Blade 1996 Drama 9 4 938628450
## 9 1358 Sling Blade 1996 Drama 10 5 942766420
## 10 1423 Hearts and Minds 1996 Drama 10 4 942766420
## # ... with 572 more rowsSekarang, kolom genres hanya berisi satu nilai yaitu Drama sehingga kita bisa harus kolom tersebut
movielens %>%
filter(year %in% c(1995, 1996) & genres == 'Drama') %>%
select(-genres)## # A tibble: 582 x 6
## movieId title year userId rating timestamp
## <int> <chr> <int> <int> <dbl> <int>
## 1 31 Dangerous Minds 1995 1 2.5 1260759144
## 2 62 Mr. Holland's Opus 1995 2 3 835355749
## 3 1358 Sling Blade 1996 6 2 1109258181
## 4 31 Dangerous Minds 1995 7 3 851868750
## 5 40 Cry, the Beloved Country 1995 7 4 851866901
## 6 1358 Sling Blade 1996 8 0.5 1154474527
## 7 26 Othello 1995 9 3 938628655
## 8 1358 Sling Blade 1996 9 4 938628450
## 9 1358 Sling Blade 1996 10 5 942766420
## 10 1423 Hearts and Minds 1996 10 4 942766420
## # ... with 572 more rows5.3.6 Menambah kolom: mutate()
Selain menggunakan kolom yang sudah tersedia dalam data, seringkali kita ingin membuat kolom baru yang merupakan turunan dari kolom yang sudah ada. Dalam movielens, kolom timestamp ditulis dalam format unix timestamp (jumlah detik dihitung sejak 1 Januari 1970, jam 00:00:00 UTC). Agar lebih mudah dipahami, kita dapat membuat kolom baru dengan mengubah kolom tersebut ke format datetime.
movielens %>%
mutate(ts = as.POSIXct(timestamp, origin = "1970-01-01")) %>%
select(-timestamp)## # A tibble: 100,004 x 7
## movieId title year genres userId rating ts
## <int> <chr> <int> <fct> <int> <dbl> <dttm>
## 1 31 Dangerous Minds 1995 Drama 1 2.5 2009-12-14 09:52:24
## 2 1029 Dumbo 1941 Animation|Ch~ 1 3 2009-12-14 09:52:59
## 3 1061 Sleepers 1996 Thriller 1 3 2009-12-14 09:53:02
## 4 1129 Escape from Ne~ 1981 Action|Adven~ 1 2 2009-12-14 09:53:05
## 5 1172 Cinema Paradis~ 1989 Drama 1 4 2009-12-14 09:53:25
## 6 1263 Deer Hunter, T~ 1978 Drama|War 1 2 2009-12-14 09:52:31
## 7 1287 Ben-Hur 1959 Action|Adven~ 1 2 2009-12-14 09:53:07
## 8 1293 Gandhi 1982 Drama 1 2 2009-12-14 09:52:28
## 9 1339 Dracula (Bram ~ 1992 Fantasy|Horr~ 1 3.5 2009-12-14 09:52:05
## 10 1343 Cape Fear 1991 Thriller 1 2 2009-12-14 09:52:11
## # ... with 99,994 more rowsContoh lain, kita ingin membuat kolom baru yang menyatakan bahwa film berjenis Drama atau bukan:
movielens %>%
mutate(isDrama = grepl("Drama", genres))## # A tibble: 100,004 x 8
## movieId title year genres userId rating timestamp isDrama
## <int> <chr> <int> <fct> <int> <dbl> <int> <lgl>
## 1 31 Dangerous Minds 1995 Drama 1 2.5 1.26e9 TRUE
## 2 1029 Dumbo 1941 Animation|Chi~ 1 3 1.26e9 TRUE
## 3 1061 Sleepers 1996 Thriller 1 3 1.26e9 FALSE
## 4 1129 Escape from New~ 1981 Action|Advent~ 1 2 1.26e9 FALSE
## 5 1172 Cinema Paradiso~ 1989 Drama 1 4 1.26e9 TRUE
## 6 1263 Deer Hunter, The 1978 Drama|War 1 2 1.26e9 TRUE
## 7 1287 Ben-Hur 1959 Action|Advent~ 1 2 1.26e9 TRUE
## 8 1293 Gandhi 1982 Drama 1 2 1.26e9 TRUE
## 9 1339 Dracula (Bram S~ 1992 Fantasy|Horro~ 1 3.5 1.26e9 FALSE
## 10 1343 Cape Fear 1991 Thriller 1 2 1.26e9 FALSE
## # ... with 99,994 more rowsKedua perintah di atas dapat digabungkan menjadi
movielens %>%
mutate(ts = as.POSIXct(timestamp, origin = "1970-01-01"),
isDrama = grepl("Drama", genres)) %>%
select(-timestamp)## # A tibble: 100,004 x 8
## movieId title year genres userId rating ts isDrama
## <int> <chr> <int> <fct> <int> <dbl> <dttm> <lgl>
## 1 31 Dangerous ~ 1995 Drama 1 2.5 2009-12-14 09:52:24 TRUE
## 2 1029 Dumbo 1941 Animatio~ 1 3 2009-12-14 09:52:59 TRUE
## 3 1061 Sleepers 1996 Thriller 1 3 2009-12-14 09:53:02 FALSE
## 4 1129 Escape fro~ 1981 Action|A~ 1 2 2009-12-14 09:53:05 FALSE
## 5 1172 Cinema Par~ 1989 Drama 1 4 2009-12-14 09:53:25 TRUE
## 6 1263 Deer Hunte~ 1978 Drama|War 1 2 2009-12-14 09:52:31 TRUE
## 7 1287 Ben-Hur 1959 Action|A~ 1 2 2009-12-14 09:53:07 TRUE
## 8 1293 Gandhi 1982 Drama 1 2 2009-12-14 09:52:28 TRUE
## 9 1339 Dracula (B~ 1992 Fantasy|~ 1 3.5 2009-12-14 09:52:05 FALSE
## 10 1343 Cape Fear 1991 Thriller 1 2 2009-12-14 09:52:11 FALSE
## # ... with 99,994 more rows5.3.7 Meringkas data: summarise()
summarise() berfungsi untuk meringkas atau agregasi baris data, seperti untuk menghitung banyaknya pengamatan, nilai tengah, total, nilai maksimum dan minimum, dan lain-lain.
movielens %>%
summarise(uniqueTitle = n_distinct(title),
totalReview = n(),
avgRating = mean(rating))## # A tibble: 1 x 3
## uniqueTitle totalReview avgRating
## <int> <int> <dbl>
## 1 8832 100004 3.54Contoh di atas menghitung banyaknya baris, banyaknya judul unik, dan rata-rata dari rating dalam keseluruhan dataframe, dan meringkasnya menjadi satu baris. Kita dapat melakukan agregasi untuk setiap kelompok/group/class satu kolom atau lebih, dengan memanfaatkan perintah group_by(). Misalnya, contoh di atas dapat dimodifikasi agar perhitungan dilakukan untuk setiap tahun rilis. Dengan menambahkan group_by(year), maka perintah yang dimaksud adalah sebagai berikut:
movielens %>%
group_by(year) %>%
summarise(uniqueTitle = n_distinct(title),
totalReview = n(),
avgRating = mean(rating))## # A tibble: 104 x 4
## year uniqueTitle totalReview avgRating
## <int> <int> <int> <dbl>
## 1 1902 1 6 4.33
## 2 1915 1 2 3
## 3 1916 1 1 3.5
## 4 1917 1 2 4.25
## 5 1918 1 2 4.25
## 6 1919 1 1 3
## 7 1920 3 15 3.7
## 8 1921 5 12 4.42
## 9 1922 6 28 3.80
## 10 1923 3 3 4.17
## # ... with 94 more rowsTerlihat bahwa kolom tahun bersifat unik, artinya satu tahun hanya menempati satu baris.
mutate() juga dapat dipasangkan dengan group_by(), sehingga kolom baru yang terbentu akan berisi nilai agregat yang dihitung per grup. Misal
movielens %>%
group_by(year) %>%
mutate(uniqueTitle = n_distinct(title),
totalReview = n(),
avgRating = mean(rating)) %>%
filter(year < 1920) ## # A tibble: 14 x 10
## # Groups: year [6]
## movieId title year genres userId rating timestamp uniqueTitle totalReview
## <int> <chr> <int> <fct> <int> <dbl> <int> <int> <int>
## 1 7065 Birth ~ 1915 Drama|~ 262 2.5 1.43e9 1 2
## 2 32898 Trip t~ 1902 Action~ 262 3 1.43e9 1 6
## 3 32898 Trip t~ 1902 Action~ 299 4.5 1.34e9 1 6
## 4 32898 Trip t~ 1902 Action~ 378 4 1.44e9 1 6
## 5 3309 Dog's ~ 1918 Comedy 468 4.5 1.30e9 1 2
## 6 7065 Birth ~ 1915 Drama|~ 468 3.5 1.30e9 1 2
## 7 8511 Immigr~ 1917 Comedy 468 4.5 1.30e9 1 2
## 8 32898 Trip t~ 1902 Action~ 468 4.5 1.30e9 1 6
## 9 62383 20,000~ 1916 Action~ 468 3.5 1.30e9 1 1
## 10 72626 Billy ~ 1919 Comedy~ 468 3 1.30e9 1 1
## 11 32898 Trip t~ 1902 Action~ 481 5 1.44e9 1 6
## 12 32898 Trip t~ 1902 Action~ 547 5 1.43e9 1 6
## 13 3309 Dog's ~ 1918 Comedy 554 4 1.01e9 1 2
## 14 8511 Immigr~ 1917 Comedy 648 4 1.18e9 1 2
## # ... with 1 more variable: avgRating <dbl>Perhatikan output diatas, untuk kelompok tahun yang sama, maka uniqueTitle, totalReview dan avgRating juga sama nilainya.
5.3.8 Mengurutkan baris: arrange()
Data yang terurut umumnya lebih mudah dibaca. Di paket dplyr kita dapat mengurutkan dataframe berdasarkan kolom tertentu dengan fungsi arrange(). Contoh sebelumnya, misalnya, dapat kita urutkan dari tahun terlama ke tahun terbaru sebagai berikut:
movielens %>%
group_by(year) %>%
mutate(uniqueTitle = n_distinct(title),
totalReview = n(),
avgRating = mean(rating)) %>%
filter(year < 1920) %>%
arrange(year)## # A tibble: 14 x 10
## # Groups: year [6]
## movieId title year genres userId rating timestamp uniqueTitle totalReview
## <int> <chr> <int> <fct> <int> <dbl> <int> <int> <int>
## 1 32898 Trip t~ 1902 Action~ 262 3 1.43e9 1 6
## 2 32898 Trip t~ 1902 Action~ 299 4.5 1.34e9 1 6
## 3 32898 Trip t~ 1902 Action~ 378 4 1.44e9 1 6
## 4 32898 Trip t~ 1902 Action~ 468 4.5 1.30e9 1 6
## 5 32898 Trip t~ 1902 Action~ 481 5 1.44e9 1 6
## 6 32898 Trip t~ 1902 Action~ 547 5 1.43e9 1 6
## 7 7065 Birth ~ 1915 Drama|~ 262 2.5 1.43e9 1 2
## 8 7065 Birth ~ 1915 Drama|~ 468 3.5 1.30e9 1 2
## 9 62383 20,000~ 1916 Action~ 468 3.5 1.30e9 1 1
## 10 8511 Immigr~ 1917 Comedy 468 4.5 1.30e9 1 2
## 11 8511 Immigr~ 1917 Comedy 648 4 1.18e9 1 2
## 12 3309 Dog's ~ 1918 Comedy 468 4.5 1.30e9 1 2
## 13 3309 Dog's ~ 1918 Comedy 554 4 1.01e9 1 2
## 14 72626 Billy ~ 1919 Comedy~ 468 3 1.30e9 1 1
## # ... with 1 more variable: avgRating <dbl>5.3.9 Gabungan beberapa fungsi sekaligus
Setelah mempraktikan bagaimana menggunakan fungsi-fungsi dasar dplyr, mari gabungkan beberapa fungsi dalam satu perintah.
Contoh 1: Katakan untuk setiap film drama, kita ingin menghitung berapa banyak penilaian yang diberikan pada tahun perdana dan tahun-tahun setelahnya. Hasilnya diurutkan dari yang mendapat penilaian terbanyak di tahun perdana.
movielens %>%
filter(grepl("Drama", genres)) %>%
mutate(yearRating = as.numeric(format(as.POSIXct(timestamp, origin = "1970-01-01"), "%Y"))) %>%
mutate(firstYear = year == yearRating, nextYear = year < yearRating) %>%
group_by(title) %>%
summarise(firstYear = sum(firstYear), nextYear = sum(nextYear)) %>%
arrange(desc(firstYear))## # A tibble: 4,249 x 3
## title firstYear nextYear
## <chr> <int> <int>
## 1 Fargo 19 205
## 2 Gladiator 19 153
## 3 American Beauty 18 202
## 4 Blair Witch Project, The 18 68
## 5 Ex Machina 18 8
## 6 High Fidelity 18 70
## 7 Dark Knight, The 17 104
## 8 Sixth Sense, The 17 176
## 9 Erin Brockovich 16 69
## 10 Eraser 14 55
## # ... with 4,239 more rowsContoh 2: Kita akan menampilkan satu film dengan rata-rata rating terbaik untuk setiap tahun perilisan. Jika ada beberapa film yang mempunyai rating tertinggi, maka dipilih film dengan jumlah rating terbanyak. Hasil akhir berupa dataframe dengan kolom tahun, judul dan rata-rata rating.
movielens %>%
group_by(year, title) %>%
summarise(avgRating = mean(rating), nRating = n()) %>%
group_by(year) %>%
arrange(year, desc(avgRating), desc(nRating)) %>%
mutate(rn = row_number()) %>%
filter(rn == 1) %>%
select(-rn, -nRating) %>%
ungroup()## `summarise()` has grouped output by 'year'. You can override using the `.groups` argument.## # A tibble: 104 x 3
## year title avgRating
## <int> <chr> <dbl>
## 1 1902 Trip to the Moon, A (Voyage dans la lune, Le) 4.33
## 2 1915 Birth of a Nation, The 3
## 3 1916 20,000 Leagues Under the Sea 3.5
## 4 1917 Immigrant, The 4.25
## 5 1918 Dog's Life, A 4.25
## 6 1919 Billy Blazes, Esq. 3
## 7 1920 Cabinet of Dr. Caligari, The (Cabinet des Dr. Caligari., Das) 4
## 8 1921 Goat, The 5
## 9 1922 Cops 5
## 10 1923 Our Hospitality 4.5
## # ... with 94 more rowsDari hasil eksplorasi di atas, paket dplyr yang merupakan salah satu bagian inti dari paket tidyverse merupakan alat yang bisa diandalkan untuk manipulasi dataframe dalam R. Meskipun demikian, untuk keperluan yang lebih komplek, dplyr membutuhkan fungsi-fungsi yang tersedia di paket lain, baik itu paket bawaan seperti base dan utils, maupun paket lain. Misalnya untuk mengolah data string/text bisa menggunakan paket stringr, data berformat tanggal dan waktu bisa menggunakan paket lubridate. Sementara untuk melakukan pivoting atau un-pivoting bisa menggunakan paket tidyr.
Contoh-contoh lain dalam menggunakan dplyr dapat dipelajari di buku R for Data Science (Wickham and Grolemund 2017).
5.4 Join/Merge Dataframe
Join atau merge merupakan proses penggabungan dua dataframe berdasarkan kolom kunci tertentu. Dalam dplyr/tidyverse dikenal beberapa jenis join yaitu inner_join(), semi_join(), left_join(), right_join(),full_join(), dan anti_join().
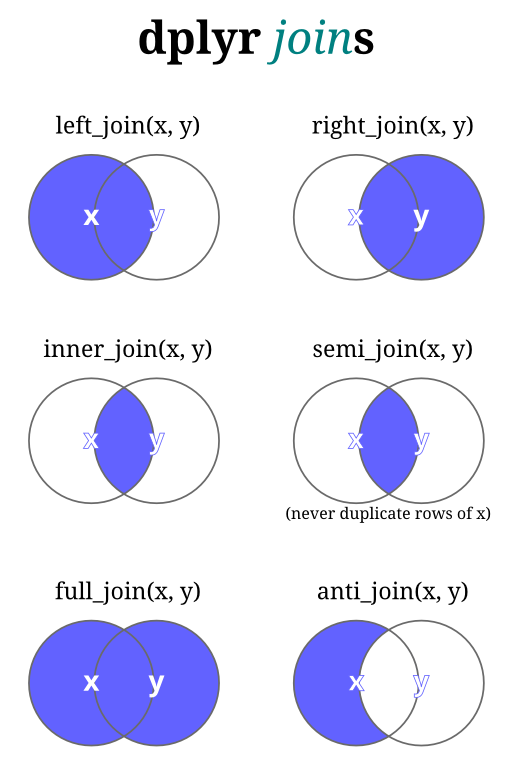
Join dalam tidyverse. Sumber gambar: Minnier & Niederhausen)
Kita akan mempraktikan penggunaan ke-enam jenis join tersebut menggunakan data berikut ini. Seluruh pembahasan dalam sub-bagian join/merge diambil dari stat545.com.
superheroes <- tibble::tribble(
~name, ~alignment, ~gender, ~publisher,
"Magneto", "bad", "male", "Marvel",
"Storm", "good", "female", "Marvel",
"Mystique", "bad", "female", "Marvel",
"Batman", "good", "male", "DC",
"Joker", "bad", "male", "DC",
"Catwoman", "bad", "female", "DC",
"Hellboy", "good", "male", "Dark Horse Comics"
)
publishers <- tibble::tribble(
~publisher, ~yr_founded,
"DC", 1934L,
"Marvel", 1939L,
"Image", 1992L
)5.4.1 inner_join(x,y)
Mengembalikan semua baris dari x yang berpasangan dengan nilai di tabel y berdasarkan kolom tertentu. Semua kolom dari kedua tabel akan ditampilkan. Jika ada multiple matches, maka seluruh kombinasi yang match tersebut akan dikembalikan.
inner_join(superheroes, publishers)## Joining, by = "publisher"## # A tibble: 6 x 5
## name alignment gender publisher yr_founded
## <chr> <chr> <chr> <chr> <int>
## 1 Magneto bad male Marvel 1939
## 2 Storm good female Marvel 1939
## 3 Mystique bad female Marvel 1939
## 4 Batman good male DC 1934
## 5 Joker bad male DC 1934
## 6 Catwoman bad female DC 19345.4.2 semi_join(x,y)
Mirip seperti inner_join() hanya saja tidak akan mengembalikan nilai duplikat. Pada semi_join, hanya mengembalikan kolom-kolom dari tabel x.
semi_join(superheroes, publishers)## Joining, by = "publisher"## # A tibble: 6 x 4
## name alignment gender publisher
## <chr> <chr> <chr> <chr>
## 1 Magneto bad male Marvel
## 2 Storm good female Marvel
## 3 Mystique bad female Marvel
## 4 Batman good male DC
## 5 Joker bad male DC
## 6 Catwoman bad female DC5.4.3 left_join(x,y)
Mengembalikan semua baris dari x. Jika ada match dengan tabel y, maka data akan dikembalikan. Jika tidak match, maka akan diisi dengan NA. Pada left_join() kolom-kolom dari tabel x dan y dikembalikan.
left_join(superheroes, publishers)## Joining, by = "publisher"## # A tibble: 7 x 5
## name alignment gender publisher yr_founded
## <chr> <chr> <chr> <chr> <int>
## 1 Magneto bad male Marvel 1939
## 2 Storm good female Marvel 1939
## 3 Mystique bad female Marvel 1939
## 4 Batman good male DC 1934
## 5 Joker bad male DC 1934
## 6 Catwoman bad female DC 1934
## 7 Hellboy good male Dark Horse Comics NA5.4.4 right_join(x,y)
Kebalikannya dari left_join()
right_join(superheroes, publishers)## Joining, by = "publisher"## # A tibble: 7 x 5
## name alignment gender publisher yr_founded
## <chr> <chr> <chr> <chr> <int>
## 1 Magneto bad male Marvel 1939
## 2 Storm good female Marvel 1939
## 3 Mystique bad female Marvel 1939
## 4 Batman good male DC 1934
## 5 Joker bad male DC 1934
## 6 Catwoman bad female DC 1934
## 7 <NA> <NA> <NA> Image 19925.4.5 full_join(x,y)
Mengembalikan semua baris dari tabel x dan y baik yang berpasangan maupun tidak. Untuk baris yang tidak berpasangan akan diisi dengan NA. full_join() mengembalikan kolom-kolom dari kedua tabel.
full_join(superheroes, publishers)## Joining, by = "publisher"## # A tibble: 8 x 5
## name alignment gender publisher yr_founded
## <chr> <chr> <chr> <chr> <int>
## 1 Magneto bad male Marvel 1939
## 2 Storm good female Marvel 1939
## 3 Mystique bad female Marvel 1939
## 4 Batman good male DC 1934
## 5 Joker bad male DC 1934
## 6 Catwoman bad female DC 1934
## 7 Hellboy good male Dark Horse Comics NA
## 8 <NA> <NA> <NA> Image 19925.4.6 anti_join(x,y)
Mengembalikan baris-baris dari x yang tidak berpasangan dengan y. Hanya kolom dari x yang dikembalikan.
anti_join(superheroes, publishers)## Joining, by = "publisher"## # A tibble: 1 x 4
## name alignment gender publisher
## <chr> <chr> <chr> <chr>
## 1 Hellboy good male Dark Horse Comics5.5 Reshaping Dataframe
Reshaping atau pivoting merupakan proses mengubah format tabel, dari wide ke long atau sebaliknya. Namun umumnya, analis data lebih tertarik untuk mendapatkan format data yang “tidy.” Suatu data disebut tidy apabila:
- Setiap kolom adalah variabel/peubah
- Setiap baris adalah pengamatan
- Setiap cell adalah nilai tunggal
Format tidy data merupakan format penyimpanan standar dalam tidyverse. Apabila data kita sudah berformat tidy, maka akan memudahkan untuk dilakukan analisis.
Selain dengan paket base (seperti yang telah dipelajari di bab sebelumnya), salah satu paket yang dapat digunakan untuk melakukan reshape data adalah tidyr yang merupakan bagian dari paket tidyverse.
Apabila belum menginstal paket tersebut, dipersilakan menginstalnya terlebih dahulu dan load kedalam workspace:
install.packages("tidyr")library(tidyr)Untuk praktik kita akan menggunakan data set airquality yang ada pada paket datasets (Sumber).
data(airquality)
head(airquality)## Ozone Solar.R Wind Temp Month Day
## 1 41 190 7.4 67 5 1
## 2 36 118 8.0 72 5 2
## 3 12 149 12.6 74 5 3
## 4 18 313 11.5 62 5 4
## 5 NA NA 14.3 56 5 5
## 6 28 NA 14.9 66 5 65.5.1 Long ke wide
Data airquality berformat long. Misalnya kita akan mengubahnya menjadi format wide untuk kolom Month sebagai nama dan Temp sebagai nilai. Fungsi yang dapat digunakan adalah pivot_wider()
air_wide <-
airquality %>%
select(Temp, Month, Day) %>%
pivot_wider(names_from = Month,
values_from = Temp,
names_prefix = "Month")
air_wide## # A tibble: 31 x 6
## Day Month5 Month6 Month7 Month8 Month9
## <int> <int> <int> <int> <int> <int>
## 1 1 67 78 84 81 91
## 2 2 72 74 85 81 92
## 3 3 74 67 81 82 93
## 4 4 62 84 84 86 93
## 5 5 56 85 83 85 87
## 6 6 66 79 83 87 84
## 7 7 65 82 88 89 80
## 8 8 59 87 92 90 78
## 9 9 61 90 92 90 75
## 10 10 69 87 89 92 73
## # ... with 21 more rowsSekarang tabel berformat wide, yang disusun berdasarkan baris Day dan kolom Month5, Month6, dan seterusnya. Nilai dalam setiap cell adalah Temp.
5.5.2 Wide ke long
Jika tabel berupa format wide, kita bisa mengubahnya menjadi long dengan perintah pivot_longer().
air_long <-
airquality %>%
pivot_longer(cols = Ozone:Temp,
names_to = "Variable",
values_to = "Value")
air_long## # A tibble: 612 x 4
## Month Day Variable Value
## <int> <int> <chr> <dbl>
## 1 5 1 Ozone 41
## 2 5 1 Solar.R 190
## 3 5 1 Wind 7.4
## 4 5 1 Temp 67
## 5 5 2 Ozone 36
## 6 5 2 Solar.R 118
## 7 5 2 Wind 8
## 8 5 2 Temp 72
## 9 5 3 Ozone 12
## 10 5 3 Solar.R 149
## # ... with 602 more rowsContoh diatas mengubah tabel menjadi long, kolom Ozone hinggal Temp menjadi kolom variabel yang nilai-nilainya ditempatkan pada kolom value.